

Toilet Tissue
Modern machine learning research relies on a relatively small set of carefully curated datasets. Even in these datasets, and typically in `untidy' or raw data, practitioners are faced with significant issues of data quality and diversity which can be prohibitively labor intensive to address. Existing methods for dealing with these challenges tend to make strong assumptions about the particular issues at play, and often require a priori knowledge or metadata such as domain labels. Our work is orthogonal to these methods: we provide a unified and efficient framework for Metadata Archaeology -- uncovering and inferring metadata of examples in a dataset. This inferred metadata can bring to light biases and other data issues a posteriori.
We curate different subsets of data that might exist in a dataset (e.g. mislabeled, atypical, or out-of-distribution examples) using simple transformations, and leverage differences in learning dynamics between these curated subsets to infer metadata of interest. We compare loss trajectories against our curated subsets in order to identify training examples with similar metadata, and show that this simple approach is on par with far more sophisticated mitigation methods across different tasks: identifying and correcting mislabeled examples, identifying minority-group samples, prioritizing points relevant for training and enabling scalable human auditing of relevant examples.



The primary contributions of our work can be summarized as follows:
MAP-D can be an effective tool to audit high-dimensional datasets. Below, we plot images from four different probe categories (i.e., typical, atypical, corrupted inputs, and random outputs probe categories) for randomly selected classes from CIFAR-10, CIFAR-100 and ImageNet.
Examples surfaced via the `typical` probe category: Images surfaced through the typical probe category are mostly well centered images with typical color scheme where the only object in the image is the object of interest.
Examples surfaced via the `corrupted` probe category: Images surfaced through the corrupted probe category has a slightly higher complexity than the images surfaced through the typical probe, while being slightly lower in complexity as compared to atypical examples. They form a natural transition between typical and atypical examples.
Examples surfaced via the `atypical` probe category: Images surfaced through the atypical probe category present the object in unusual settings or vantage points, or features differences in color scheme from the typical variants.
Examples surfaced via the `random outputs` probe category: Images surfaced through the random outputs probe category represent images that would be hard for a human to classify, might contain multiple labels which are appropriate for that image, or might even be out-of-distribution w.r.t. the rest of the data distribution.
Toilet Tissue
Toilet Tissue
Toilet Tissue
Toilet Tissue

Ambulance

Ambulance

Ambulance

Ambulance

Assault Rifle

Assault Rifle

Assault Rifle

Assault Rifle

Balloon

Balloon

Balloon

Balloon

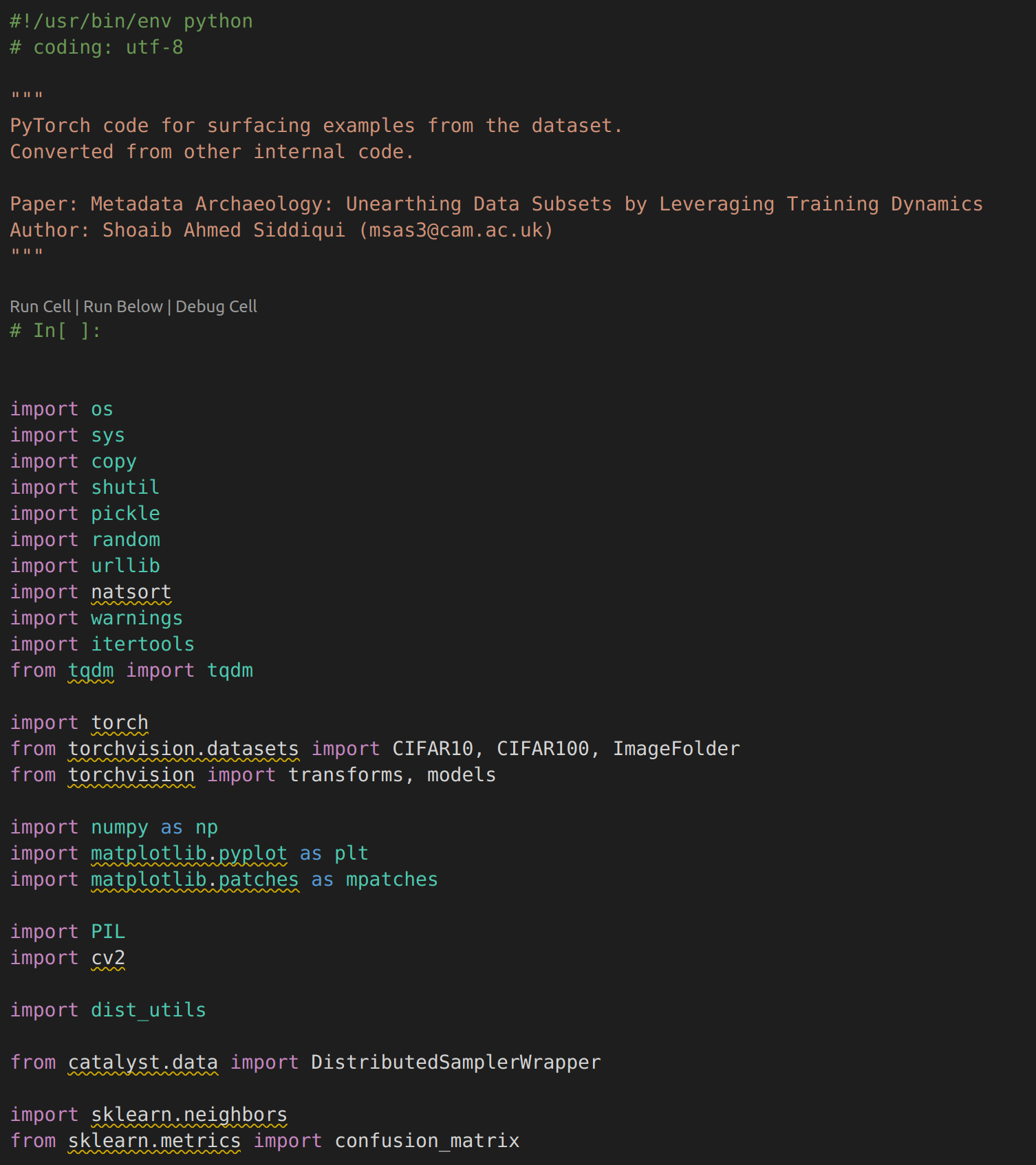
Bathtub

Bathtub
Bathtub

Bathtub

Bulletproof Vest

Bulletproof Vest

Bulletproof Vest

Bulletproof Vest

Cannon

Cannon

Cannon

Cannon

Container Ship

Container Ship

Container Ship

Container Ship

Desktop Computer

Desktop Computer

Desktop Computer

Desktop Computer

Digital Watch

Digital Watch

Digital Watch

Digital Watch

Garbage Truck

Garbage Truck

Garbage Truck

Garbage Truck

iPod

iPod

iPod

iPod

Microwave

Microwave

Microwave

Microwave

Milk Can

Milk Can

Milk Can

Milk Can

Missile

Missile

Missile

Missile

Mountain Bike

Mountain Bike

Mountain Bike

Mountain Bike

Plastic Bag

Plastic Bag

Plastic Bag

Plastic Bag

Safe

Safe

Safe

Safe

Tank

Tank

Tank

Tank

Toaster

Toaster

Toaster

Toaster

Whiskey Jug

Whiskey Jug

Whiskey Jug

Whiskey Jug

Street Sign

Street Sign

Street Sign

Street Sign

Pineapple

Pineapple

Pineapple

Pineapple

Banana

Banana

Banana

Banana

Baby

Baby

Baby

Baby

Man

Man

Man

Man

Bicycle

Bicycle

Bicycle

Bicycle

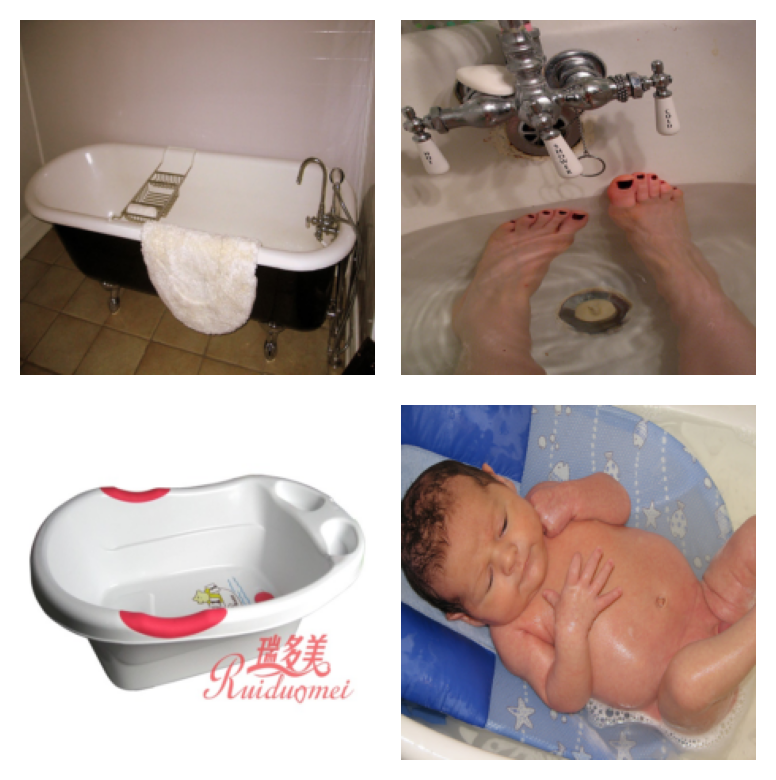
Bowl

Bowl

Bowl
Bowl

Clock

Clock

Clock

Clock

Cloud

Cloud

Cloud

Cloud

Couch

Couch

Couch

Couch

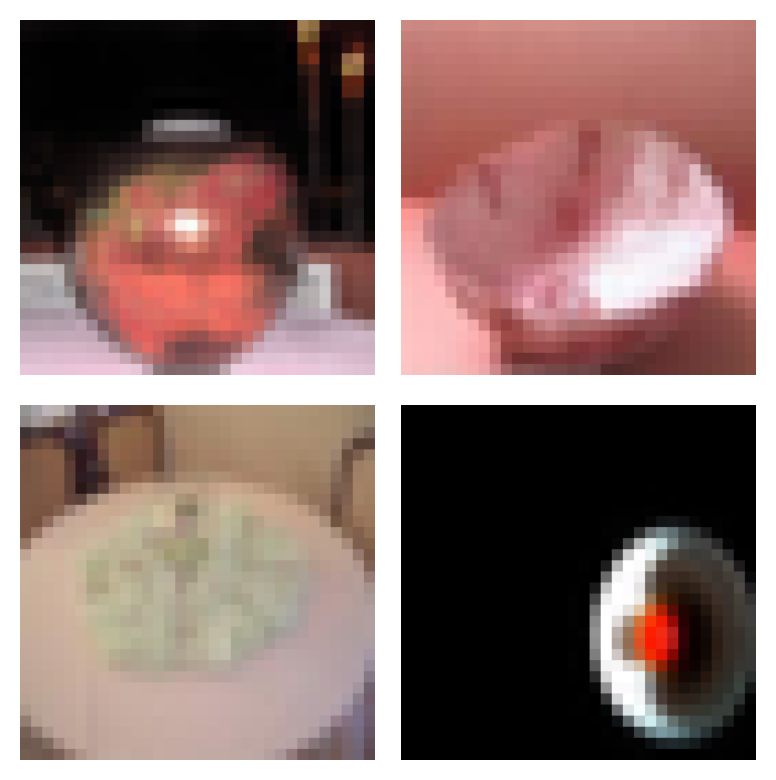
Crab
Crab

Crab
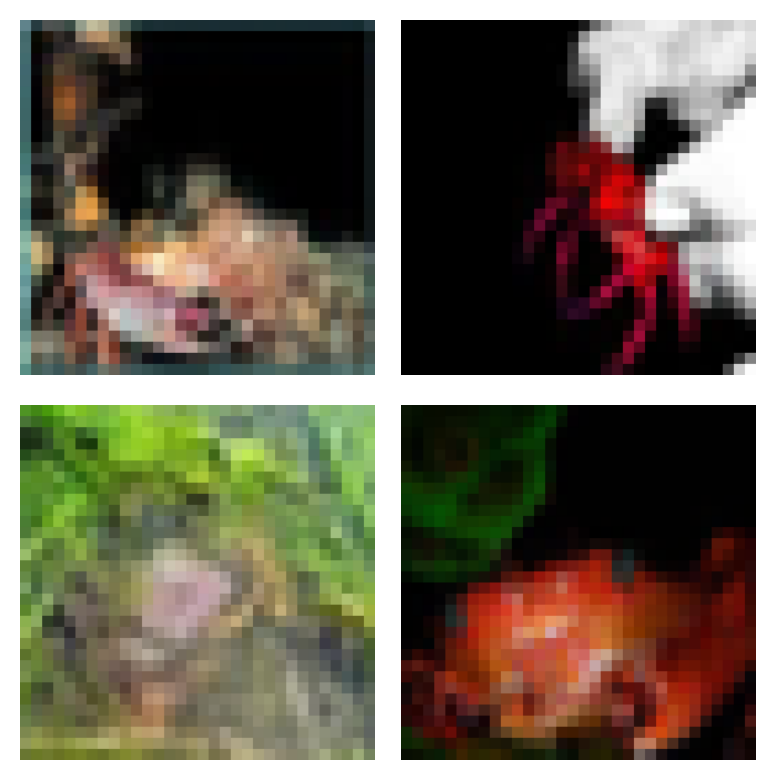
Crab

Dinosaur

Dinosaur

Dinosaur

Dinosaur

Flatfish

Flatfish

Flatfish

Flatfish

Lion

Lion

Lion

Lion

House

House

House

House

Lobster
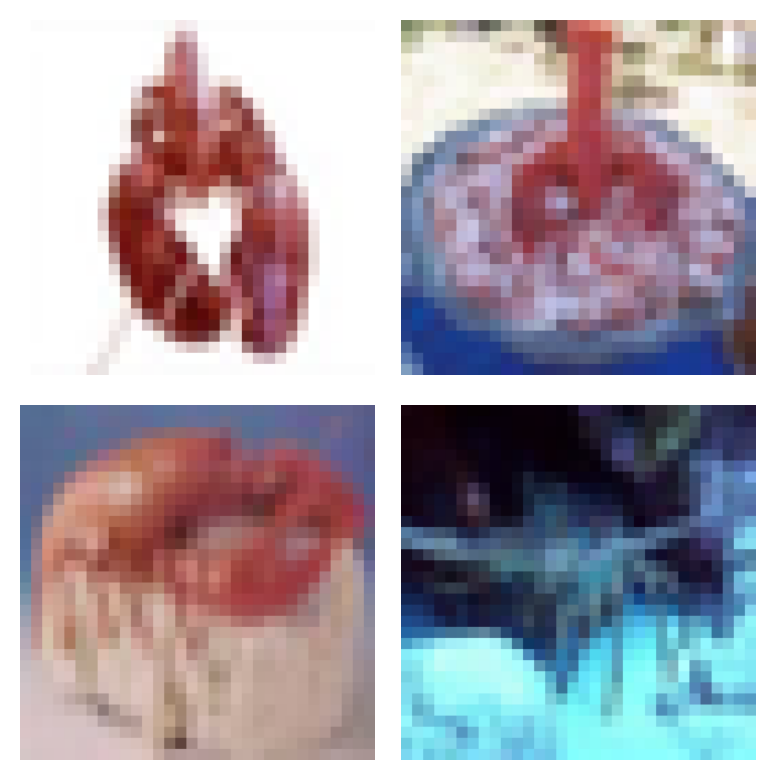
Lobster

Lobster

Lobster

Porcupine

Porcupine

Porcupine

Porcupine

Bee

Bee

Bee
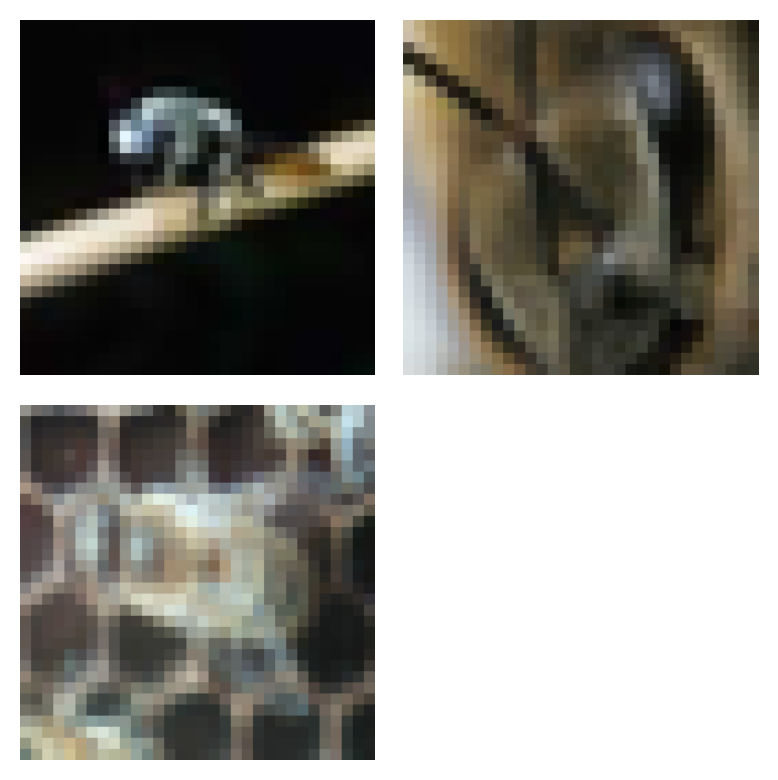
Bee

Ray

Ray

Ray

Ray

Plate

Plate

Plate

Plate

Sea

Sea

Sea

Sea

Table

Table

Table

Table

Skyscraper

Skyscraper

Skyscraper

Skyscraper

Telephone

Telephone

Telephone

Telephone

Wardrobe

Wardrobe

Wardrobe

Wardrobe
Pre-computed output Images for CIFAR-10/CIFAR-100/ImageNet are available here.
We welcome additional discussion and code contributions on the topic of this work. A comprehensive introduction of the methodology, experiment framework and results can be found in our paper and open source code.
If you use this software, please consider citing:
@article{siddiqui2022metadataarchaeology,
title={Metadata Archaeology: Unearthing Data Subsets by Leveraging Training Dynamics},
author={Siddiqui, Shoaib Ahmed and Rajkumar, Nitarshan and Maharaj, Tegan and Krueger, David and Hooker, Sara},
journal={arXiv preprint},
year={2022}
}